
No, AI Can't Predict Crime Before It Happens
Or, Why You Shouldn't Get Your News From Social Media

This blog is primarily dedicated to long-form analysis, which is why I hibernate for weeks or months at a time. Currently working on a long, long piece debunking a prominent pseudohistorian, which will be a long time in the oven yet. But I wanted to very briefly address an example of why I militate against getting your news from social media.
Just this morning, I catch this in my Substack Notes feed:
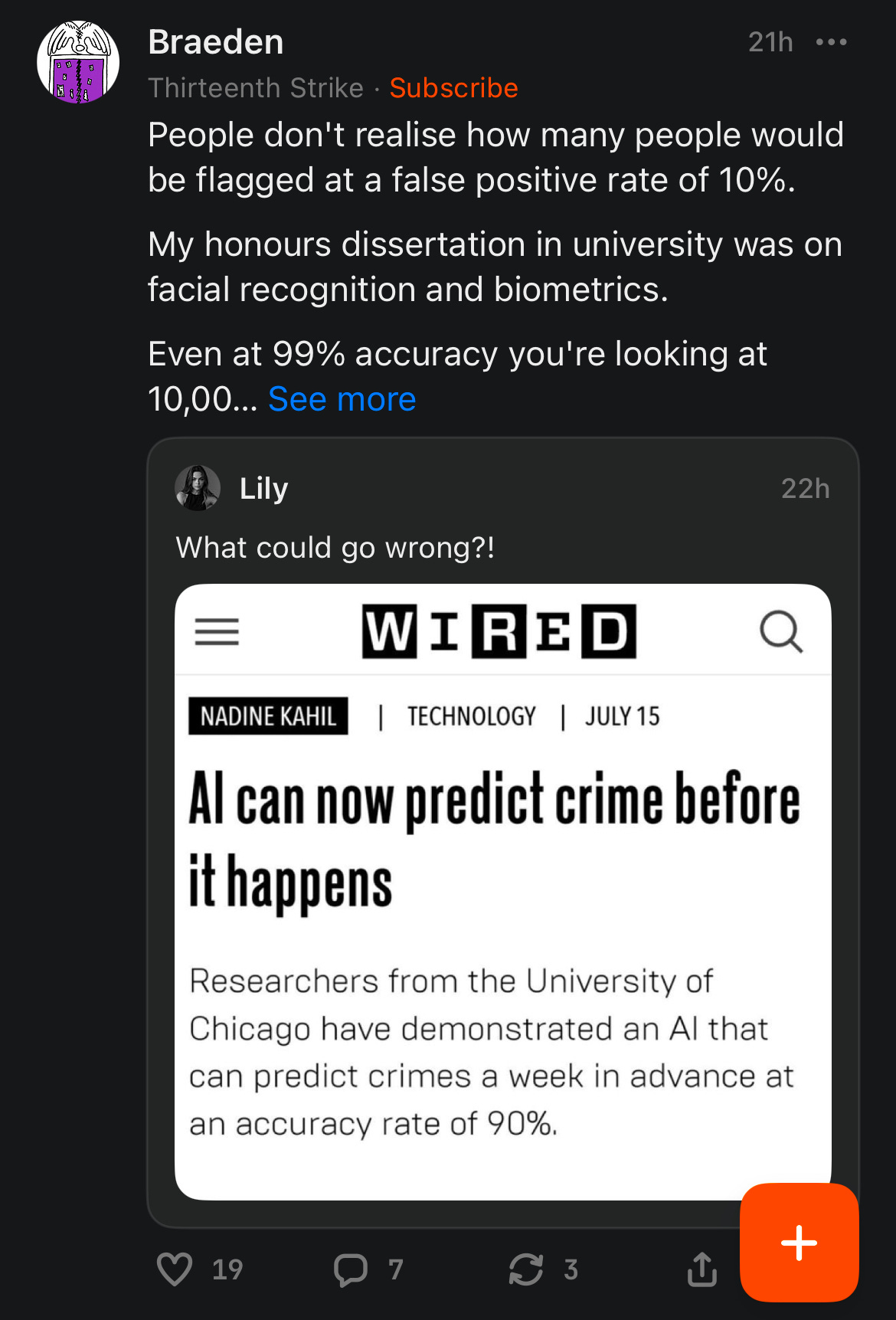
The comments of both posts are full of Minority Report references and people panicking about the damage to their civil liberties.
Now, this happened to pique my interest, because I’ve got a couple pieces scheduled for the Maroon next quarter and if someone on campus is trying to make AI crime prediction, that’s something worth writing on.
But lo and behold, when I look it up, I discover that the piece isn’t recent: it’s from 2022. Moreover, it’s not even on the main WIRED website, as best as I can tell, only on WIRED Middle East.
Actually reading the article, it’s plainly garbage. The links in the first paragraph are on ‘University of Chicago’ and ‘AI’ are to the main website for the university and to WIRED Middle East’s own ‘AI’ tag, respectively. Only at the bottom does it mention the actual source, a paper published in Nature, which has a broken link and no proper citation.
Only on tracking down the paper myself (Rotaru, V., Huang, Y., Li, T. et al. Event-level prediction of urban crime reveals a signature of enforcement bias in US cities. Nat Hum Behav 6, 1056–1068 (2022). https://doi.org/10.1038/s41562-022-01372-0) do I discover that the headline is just wrong. The authors were not even trying to predict future crime, they were studying how biased enforcement could be detected using similar means.
This is the standard move. Take a recent published paper, run it through a blender, put the resulting slurry on the head and subhead, open with a couple of paragraphs completely missing the point and making pop culture references, and then hide the actual contents of the paper, if you address them at all, in drip of poorly-written paragraphs nobody will read and fewer will realize contradict the header.
I’ve repeatedly insulted the state of science journalism on this blog (in at least two out of three prior articles), and I judge this to be a representative example of the genre. These articles are actively uninformative, an absolute blight, responsible for a deadly combination of confidence and ignorance in those that follow them.
But if you get your news via social media, it’s worse. In this case, as so many others, there isn’t even a URL, just a screenshot of the headline, making it all the harder to see what the actual content is. Here, the content of the posts makes it seem like this is both serious and recent. Sure, the header says July 15, which is a little while ago, but it surely means July 15 of this year? Surely, this must be a main WIRED headline from this year, not a shovelware article from a regional affiliate from two years ago? Why bother otherwise?
And yet this article has, for some reason, started to spread on other sites as well. Within less than a day, it’s being reconstituted on third-rate tech sites, and someone tried sharing it on HackerNews. On the website formerly known as Twitter (1, 2), it has shown up in tweets claiming that this is a ‘groundbreaking algorithm’, and explicitly claiming it’s from 2024. Neither is true! Luckily, these seem to have gotten much less traction than on Substack. Don’t ask me how some random cast-off article from two years ago is suddenly making the rounds again.

This brings us to the hierarchy of reliable sources.
Social Media is not a source, but it’s even less of a source when it is citing an…
<
article in the popular press about a scientific paper. By default, you should assume that any such article, even if it’s from a publication you usually find reliable, is catastrophically wrong in its depiction or interpretation of the paper…
<
which itself may be fatally flawed, especially if it’s trying to court attention in the news. If you’re seeing it in the news, the chances of this are considerably elevated.
As usual, I highlight this example not because it is especially consequential or the personalities involved in spreading it are large, but to serve as, hopefully, an especially clear example of what to avoid. The next time you are scrolling and see someone’s summary of a news article of a scientific paper, stop in your tracks and recognize that you are about to be exposed to the devil’s epistemology.
On a lighter note, I will once again thank Stuart Ritchie for sharing a certain article published in September of this year in the International Journal of Surgery Case Reports. The paper, titled ‘Practice of neurosurgery on Saturn’ by Mostofi & Peyravi, is an experimental short story satirizing medicine through the stories of patients (and doctors) engaged in… neurosurgery on Saturn. It’s rather self-explanatory, but a delightful read. I suspect this was also a hoax to demonstrate the laxity of editorial review in such journals; either that, or the editors of the IJSCR have a very good sense of humor.
Also, some advice: anytime a news or social media piece uses language like ‘groundbreaking algorithm’ you can be extremely confident they’re lying or don’t understand what they’re talking about. Big breaks and developments in this field don’t usually come from creating new algorithms, but from applying off-the-shelf technologies in effective combination, along with scaling them to new heights. This is the case for generative AI as well: the algorithms are old, the applications (and massive computing power) are new.
Until next time, have a pleasant week.